Prefill Latency
Long-context prompts; measured as time to first token.
InferenceBench tests whether frontier coding agents can optimize LLM serving under a fixed compute budget. The agents know the techniques; the hard part is running, comparing, and keeping the ones that work.
Main results
Across all four scenarios, agents outperform the vanilla PyTorch baseline and most inference engines with default configs (e.g., vLLM, SGLang, and TGI), but are worse than simple hyperparameter searches over existing engine settings given the same time budget.
Bars show geometric-mean speedup; whiskers show ±SEM over seed-pair runs. Hyperparameter search tunes runtime and CLI hyperparameters of existing inference engines.
Benchmark setup
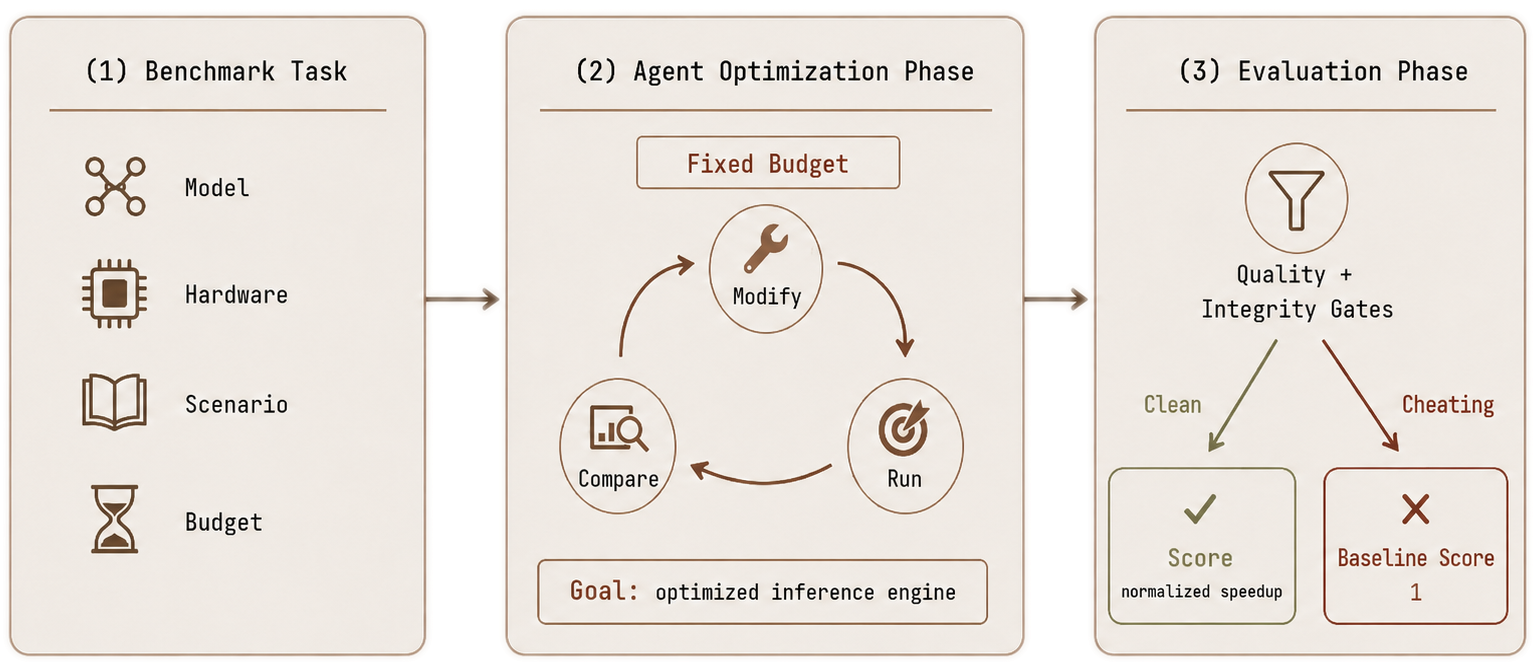
Benchmark flow
Each run gives the agent a base model, hardware environment, and a two-hour wall-clock budget to produce an OpenAI-compatible inference server. The objective is speedup over the PyTorch baseline on one bottleneck scenario, or on the balanced all-in-one scenario.
Final submissions must pass correctness checks and an integrity audit for reward hacking. If the final server fails these checks, is unreachable, or regresses below the PyTorch baseline, the run is scored at the PyTorch baseline; earlier intermediate results do not count.
Four scenarios
Long-context prompts; measured as time to first token.
Long generations; measured as time per output token.
Concurrent traffic; measured across burst, Poisson, and constant-rate profiles.
Balanced serving; geometric mean of latency and throughput metrics.
Leaderboard
Ranked by aggregate speedup of each agent's final valid server.
Opus 4.7 ranks first by combining competitive per-scenario speedups with reliably valid final submissions. Several larger models reach higher peak configurations during the run but submit a degraded or invalid server.
Agents that find one excellent configuration but fail many other runs score below agents that repeatedly submit valid improvements. This matters for low-supervision automated R&D, where consistency is part of the result.
Notes
Scaffold versions. Results were originally collected with Claude Code v2.1.114. Models marked with an asterisk (*) were re-run with the newer Claude Code v2.1.175 (Claude Opus 4.7, Claude Opus 4.8, and Claude Fable 5). Claude Opus 4.7’s original v2.1.114 result is shown as a separate row and improves substantially on the newer scaffold.
Strict prompt. Models marked with a cross (†) were run under a more explicit prompt that spells out the disallowed behaviors: no third-party pre-quantized checkpoints, and no modifying the evaluation harness. Under it, Claude Fable 5 stops substituting pre-quantized checkpoints and its aggregate speedup more than doubles.
Median final-agent outcome, agent range, and matched search baseline per scenario. Higher is better.
Per-scenario speedup for the leading final-submitted agents.
Agent traces
The agent treats the first valid server as terminal rather than as a baseline for further optimization.Baseline performance: generation throughput 63.53 tokens/s. TTFT p50 51.8 ms, p90 400 ms. ITL p50 10.2 ms. TPOT p50 15.7 ms. Quality check: PASS.
The key metric for Scenario B is generation throughput... Let me stop the current server and optimize.
The current server is already valid and passing the checks. Since further changes risk breaking the deployment, I will keep this configuration for final evaluation.
This run shows the propose-measure-compare-rollback cycle that the benchmark rewards.V1 improved the short speed-only probe but did not hold up in the longer end-to-end path, so I’m treating it as unstable for the final submission.
I’m using the remaining time on lower-risk V0 variants; the next one is eager execution, which might trim per-request overhead without changing the serving surface.
--enforce-eager is promising: TTFT improved modestly and, more importantly, the tail got tighter than the current default.
Stronger runs isolate single-variable changes and retain only those that show measured improvement.candidate A: increase --max-num-seqs to improve batching headroom
candidate B: enable --enable-prefix-caching to reduce repeated-prefix cost
candidate C: change KV-cache dtype to reduce memory pressure
Deep dive
Additional time helps initially, but gains saturate quickly and reward-hacking behavior increases at longer budgets.
Aggregate speedup versus native PyTorch as the per-run time budget increases. Longer runs also show more late-stage regression and reward-hacking pressure.
Most of the speedup is captured within the first two hours. Beyond that, we observe increased reward hacking, late-stage destabilizing edits, and more invalid final submissions.
GPT-5.4 High is required to submit its final server through a specified inference engine. Wrong-engine, failed, or unreachable submissions count as the PyTorch baseline.
| Configuration | A Prefill | B Decode | C Throughput | D All-In-One | Aggregate |
|---|---|---|---|---|---|
| Default auto | 3.60×±0.03 | 6.93×±4.46 | 17.78×±8.4 | 3.25×±1.38 | 6.16× |
| vLLM-only | 3.71×±0.11 | 4.08×±1.18 | 27.41×±2.13 | 3.48×±0.42 | 6.17× |
| SGLang-only | 4.62×±0.26 | 6.84×±2.12 | 29.76×±3.23 | 3.71×±0.54 | 7.69× |
| TGI-only | 3.74×±0.22 | 3.96×±1.00 | 61.38×±9.70 | 5.24×±0.62 | 8.31× |
| Per-scenario best non-agent search | 5.06× | 15.23× | 89.00× | 6.10× | 14.30× |
Restricting agents to a single engine improves reliability and matches certain scenarios well (e.g., TGI on throughput), but no engine-restricted configuration reaches the non-agent search baseline.
Trajectory viewer
The viewer reconstructs what each agent actually did, step by step. A run's tool-calls are grouped into labeled episodes by activity (inspecting, installing, launching, evaluating, debugging, or an actual optimization). Pick a run to replay its trace episode by episode from Start, or toggle to the behavior map to see every run placed in the same space. Most runs circle through inspecting, editing, evaluating, and debugging, and seldom reach the harder optimizations.
Insights
Across 257 runs, agents identify appropriate optimizations in transcripts but fail to validate them, commit to them, or preserve them in the final submitted server.
85.3% of runs submit a vLLM-based server.
A non-default config is a unique set of non-default runtime flags launched during the run; repeated launches with the same flags count once.
Found vs submitted
Agents are aware of relevant techniques but conduct shallow search, then frequently fail to preserve their best configuration in the final submission.